Tenere pulito e veloce il database del tuo sito wordpress: comparazione di 5 plugins on Posted by tron
Posted in Hosting Tutorial & Modifiche I migliori strumenti per analizzare e migliorare la velocità del tuo sito web on tron
Posted in Tutorial & Modifiche Come Configurare il File Robots.txt per Migliorare il Posizionamento SEO on tron
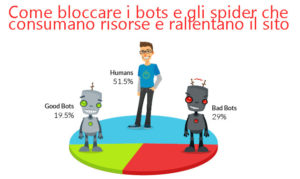
Posted in Hosting Tutorial & Modifiche Come sapere quali bots/spider rallentano il server (e come bloccarli) on tuttoblog
Posted in Tutorial & Modifiche WordPress, come passare da http a https (e aumentare le visite al sito) on magnaromagna
Posted in Hosting Tutorial & Modifiche Come scegliere un certificato SSL e rendere sicuro il sito passando al protocollo HTTPS on tuttoblog